Some of Wikipedia’s most contextually rich and factual data resides within thousands of tables across millions of articles. These data tables contain music charts, sports statistics, election results, filmographies, and so much more. They visually make it easy for humans to quickly understand the information within, but extracting them at scale as structured data is a difficult task for machines due to their unique complexity, variability, and formatting. Accessing this wealth of information has remained one of the most persistent challenges for anyone working with Wikipedia data at scale.
That changes today. We are introducing Parsed Tables to our Beta Structured Contents payloads. This phase one release makes it possible to access Wikipedia’s tabular data as ready-to-use JSON, improving downstream applications in AI/ML, knowledge graphs, search, machine learning, and large-scale research.
That changes today. We are introducing Parsed Tables to our Beta Structured Contents payloads. This phase one release makes it possible to access Wikipedia’s tabular data as ready-to-use JSON, improving downstream applications in AI/ML, knowledge graphs, search, machine learning, and large-scale research.
Why Wikipedia Tables Matter for Developers and Data Teams
Wikipedia contains millions of high-quality tables that provide valuable information on a wide range of topics. Over 60% of the information stored in Wikipedia tables is not accessible anywhere else. These tables are human-curated, timely, and often the only source for specific domain facts.
Key use cases include:
Knowledge Graphs
Populate graphs with award winners, sports statistics, discographies, and more.
AI and ML Datasets
Enrich your training data with deeply contextual machine-readable tables.
Search and Discovery
Index structured facts for more relevant, granular answers.
Fact-checking
Validate data across pages, languages, or snapshots to improve reliability.
Academic Research
Analyze and compare tables at scale across topics and languages.
Yet for most, these tables have remained out of reach due to technical hurdles. Scraping HTML, reverse-engineering templates, or writing brittle parsers is costly and error-prone, and all of these methods require high levels of maintenance, as table structures can—and often do—change at any time.
Parsed Tables Explained
Parsed Tables is a new feature in Wikimedia Enterprise Structured Contents beta endpoints. It converts Wikipedia data tables from HTML and wikitext blobs into structured, reliable JSON ready for direct integration at scale. Parsed Tables are available in all Wikipedia languages. That said, tables have been tested more extensively for English, German, French, Spanish, Italian, Portuguese, Indonesian, Welsh, and Dutch Wikipedias (as of February 2026).
Each article section with a table will have a new table_references array that includes:
- the unique identifier of any parsed table in that section.
- a
confidence_scoreto indicate how structurally consistent the table layout is.
Each table:
- is a clean structured JSON object inside a
tablesarray. - includes a unique identifier that refers back to the article section the table resides in for full context.
- includes a
confidence_scoreto indicate how structurally consistent the table layout is.
Confidence Score Explained
Each parsed table includes a confidence_score field. This value reflects how well the table’s HTML is structured and, in turn, how likely the parser extracted it accurately. It is not a measure of the quality or reliability of the data itself.
A high score (e.g. 0.9) generally means the parser is highly likely to have extracted the table accurately, while a low score (e.g. 0.35) suggests structural issues such as irregular column counts, nested rows, or merged cells that reduce parsing accuracy.
In this initial release, only tables with a confidence score of 0.5 or higher are included in the parsed output. This threshold provides coverage of more than 70% of content tables across the top tested languages. Lower-scoring tables are excluded, but are still listed in the table_references array for the relevant section with their identifier and score.
Examples of Parsed Tables
Source table: Wikipedia: All-time Olympic Games Medals Combined Totals
This is the rendered HTML version of a table that you’re used to seeing on Wikipedia:
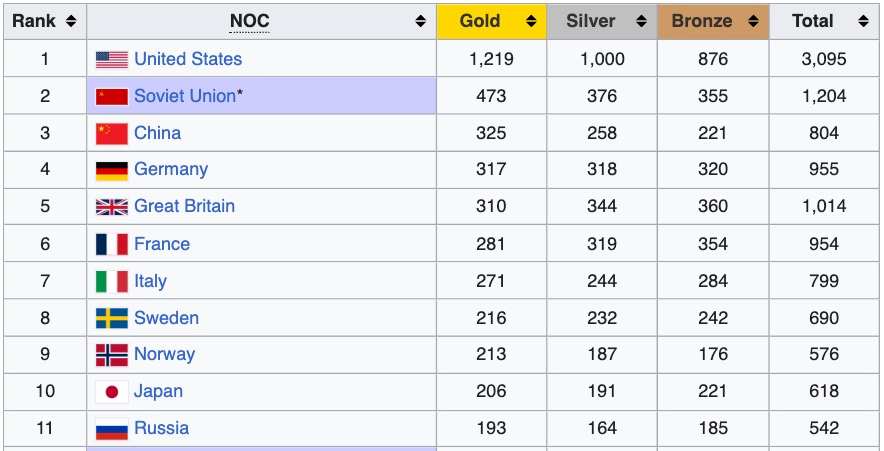
Here’s that same table in the HTML source code. A web scraper would have to extract the table data from this constantly changing, non-standardised structure.
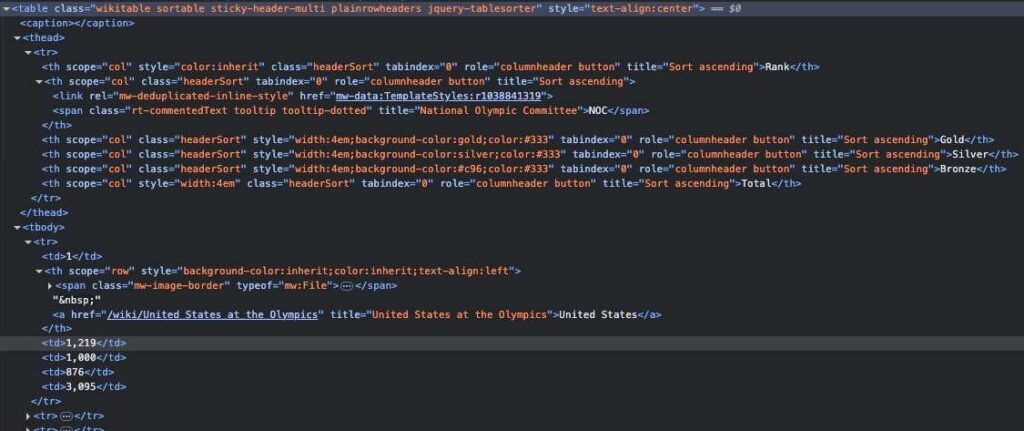
And here is that same table as a Wikitext BLOB that’s from the foundational Wikipedia APIs (also included in Enterprise APIs):
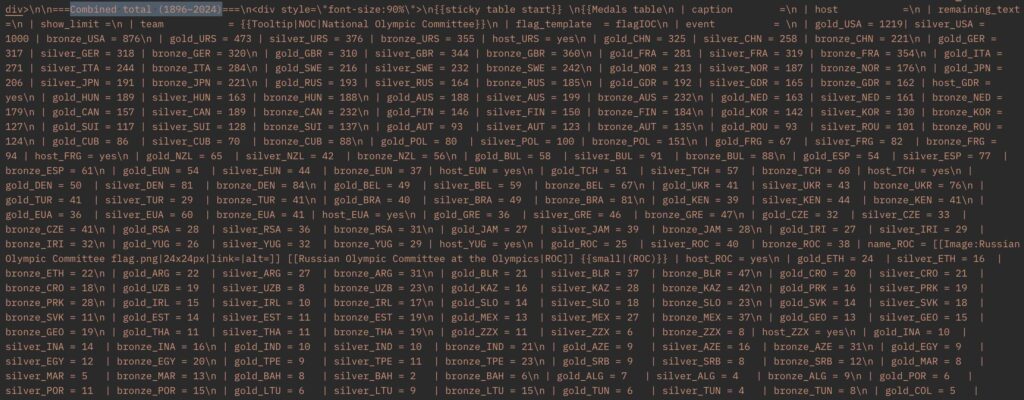
Here’s the same table again, but as an HTML BLOB supplied exclusively by Wikimedia Enterprise APIs.

Finally, let’s see what this looks like in our Structured Contents beta payloads. The first mention of any parsed table will be included within the article sections array referencing the identifier and confidence score.
{
"name": "combined_total_18962024",
"type": "section",
"has_parts": [
{
"type": "table",
"table_references": [
{
"identifier": "complete_ranked_medals_excluding_precursors.combined_total_18962024_table1",
"confidence_score": 0.9}
]
}
]
}That table_references.identifier can then be used to locate the contents of that table in the new tables array.
{
"identifier": "complete_ranked_medals_excluding_precursors.summer_olympics_18962024_table1",
"headers": [
[
{ "value": "Rank" },
{ "value": "NOC" },
{ "value": "Gold" },
{ "value": "Silver" },
{ "value": "Bronze" },
{ "value": "Total" }
]
],
"rows": [
[
{ "value": "1" },
{ "value": "United States" },
{ "value": "1,105" },
{ "value": "879" },
{ "value": "781" },
{ "value": "2,765" }
],
[
{ "value": "2" },
{ "value": "Soviet Union*" },
{ "value": "395" },
{ "value": "319" },
{ "value": "296" },
{ "value": "1,010" }
],
[
{ "value": "3" },
{ "value": "China" },
{ "value": "303" },
{ "value": "226" },
{ "value": "198" },
{ "value": "727" }
],
[
{ "value": "4" },
{ "value": "Great Britain" },
{ "value": "298" },
{ "value": "339" },
{ "value": "343" },
{ "value": "980" }
],
[
{ "value": "5" },
{ "value": "France" },
{ "value": "239" },
{ "value": "278" },
{ "value": "299" },
{ "value": "816" }
],
[ ** truncated for brevity ** ],
],
"confidence_score": 0.9
},The result: No scraping required. No additional parser codebase(s) to maintain. Just direct, reliable, structured JSON.
Get Started with Parsed Tables
Parsed Tables are available in Structured Contents endpoints in both the Snapshot API (7 supported languages) and the On-demand API (all languages):
1. If you don’t have a Wikimedia Enterprise account, sign up for free.
Free accounts allow 5,000 On-demand API requests per month, including Structured Contents endpoints.
2. Query the Structured Contents endpoints
The On-demand API endpoint /v2/structured-contents/{name} provides data for an individual article. The example below shows how to request the All-time Olympic Games Medals Combined Totals from English Wikipedia.
curl --location 'https://api.enterprise.wikimedia.com/v2/structured-contents/All-time_Olympic_Games_medal_table'
--header 'Content-Type: application/json'
--header 'Authorization: Bearer ACCESS_TOKEN'
--data '{"filters":[{"field":"is_part_of.identifier","value":"enwiki"}]}'The Snapshot API endpoint /v2/snapshots/structured-contents/{identifier}/download provides bulk Structured Contents payloads for entire projects, but requires a paid account (contact sales) or access to Wikimedia Cloud Services.
What’s Next for Parsed Tables
Parsed Tables currently covers content tables in Wikipedia articles with 0.5 or higher confidence scores. Highly complex tables, tables inside infoboxes, cells with images and links, and certain advanced markup are not yet included. However, ongoing improvements will expand coverage and add more features in phased releases.
Your feedback as a developer or data scientist is important and will directly shape future enhancements to Structured Contents features. We ask you to share your ideas, questions, and feedback with us, as it helps us enable more of Wikipedia’s knowledge to be easily accessible and machine-readable. Please provide your input via the feedback link in your account dashboard (right column), or via your Wikimedia Enterprise representative. If you’d like to inquire about being a testing partner for Structured Contents in the Snapshot API, please contact sales.