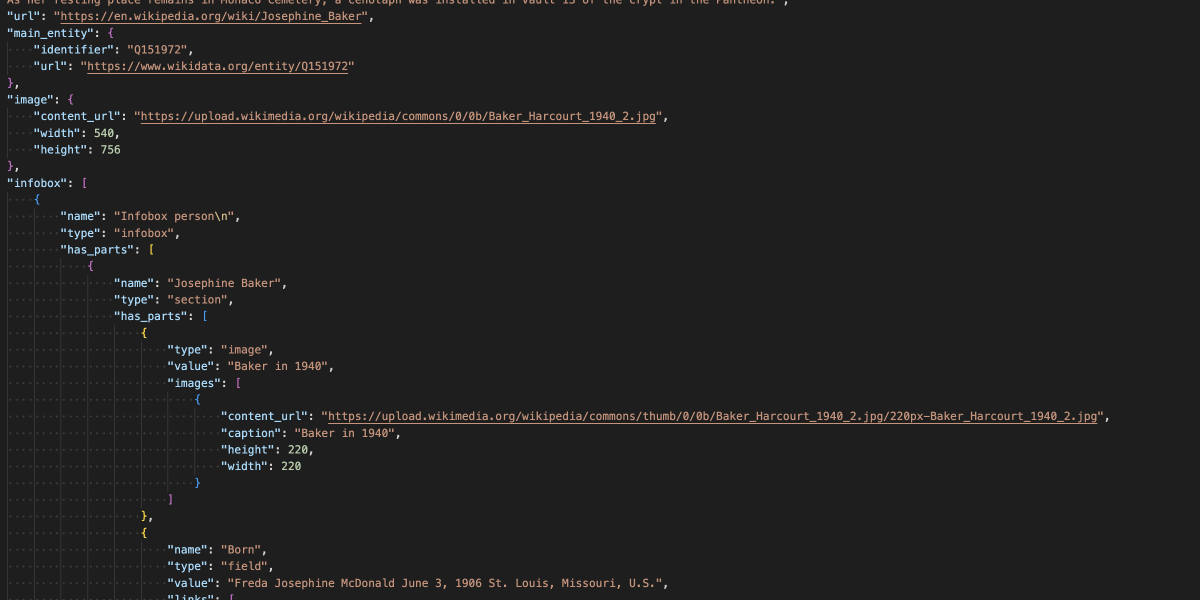
We are excited to announce the addition of a new Structured Contents initiative and endpoint to our On-demand REST API. We’ve heard all your requests for a more machine-readable API for Wikimedia data, and this is the next leap forward on that path. The response data from this new beta endpoint is similar in structure to the current /v2/articles endpoint, but includes a fully parsed Wikipedia infobox! (With more to come soon.)
Here’s what’s covered in this article:
- What is the Wikipedia Infobox?
- More Structured Data, not blobs
- How to get Wikipedia Infobox content
- Roadmap: Then, Now, and What’s Next
What is the Wikipedia Infobox?
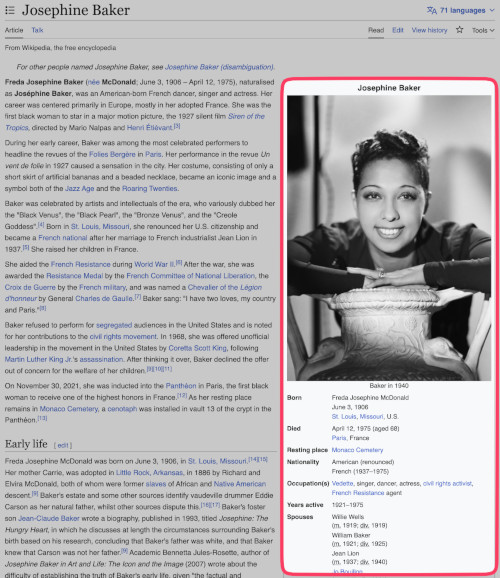
The infobox is a panel that commonly appears in the top right of a Wikipedia article. It summarizes key facts and statistics that appear in the article. Depending on the article subject you may see key dates, biographical information, important images, scientific data, and more. The infobox is a desired resource for data reusers because Wikipedia editors follow strict guidelines and work hard to keep the infobox populated with the article’s most pertinent and current metadata.
The examples here are from the Josephine Baker page.
More Structured Data, not blobs
In our spring update we covered architectural upgrades and a handful of new features including a new field called abstract which provides a summary of the article content. We have also recently introduced an object that adds the main image of the article to the articles payload.
"abstract": "Freda Josephine Baker, naturalised as Joséphine Baker, was an American-born French dancer, singer and actress. Her career was centered primarily in Europe, mostly in her adopted France. She was the first black woman to star in a major motion picture, the 1927 silent film Siren of the Tropics...""image": {
"content_url": "https://upload.wikimedia.org/wikipedia/commons/0/0b/Baker_Harcourt_1940_2.jpg",
"width": 540,
"height": 756
}These existing features were the first of a broader, ongoing endeavor to improve the machine readability of Wikimedia data. The new Structured Contents endpoint continues this evolution of Wikimedia Enterprise APIs as we actively work to expose Wikimedia project wikitext/html blobs as structured JSON.
Structured Contents Parses Wikipedia Infobox into JSON
Until now, if you wanted any data located within infoboxes you’d have to parse a very large project dump file, find the article you wanted, parse through the entire wikitext markup blob, and then grab the data needed. Doable, but quite difficult and time consuming to extract clean data.
“Is there an API for the Wikipedia infobox?”
Everybody
What if you could hit one endpoint and get exactly the data you need in standard formatted JSON? Well, it’s here!
Wikipedia article infobox data is parsed into the Structured Contents beta endpoint JSON response!
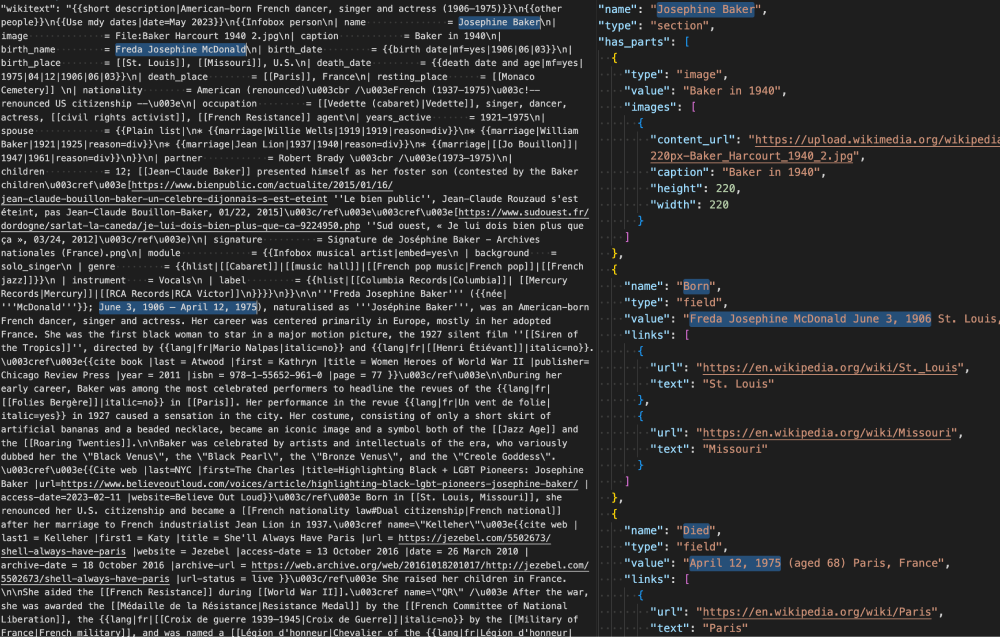
Structured Contents is part of our On-demand API, therefore you can use request filtering to grab the data you need and bypass the rest of the payload. This means you can send a request for just the article’s url, summary (abstract), and infoboxes and images; we empower you with the flexibility to choose.
How to get Wikipedia Infobox content
- Sign up for a free Wikimedia Enterprise account
- Get your API keys from the Authentication endpoint
- Make a request to the On-demand Structured Contents beta endpoint
- Enjoy your structured article content with parsed infobox JSON
If you don’t already have an account, sign up, it’s free and in a few minutes you can start making requests. Let us know if you need more.
Developer Docs for On-demand API have been updated to include the new Structured Contents endpoint and a Data Dictionary entry for infoboxes schema was added too.
We have also released an SDKs, written in Go and Python, on github to help you get started with any of our APIs. A working example of how to query the Structured Contents endpoint using our Go SDK and Python SDK are included as well.
For Wikimedia volunteers, log into Wikimedia Cloud Services to get access.
Roadmap: Then, Now, and What’s Next
When we launched Wikimedia Enterprise, our mission was clear: to create a modern, machine-readable API that could meet the reliability and scalability demands of high-volume reusers of Wikimedia project data. We’re just getting started.
The Structured Contents endpoint marks our inaugural beta release. This approach enhances transparency in our development process and facilitates more frequent improvements advantageous to reusers.
We’re actively seeking your feedback and would love to hear your experience with it, including your thoughts, requirements, and critiques. Please don’t hesitate to reach out to us. All account holders can use the “Contact Support” form in your account dashboard to share your input with our team.
Thank you for reading!
Update: Structured Contents snapshots now available too!
Update: APIs now include parsed Article sections and short description!
— Chuck Reynolds, Staff Product Manager, Growth