
News and updates from the Wikimedia Enterprise team
-
Free Wikimedia Enterprise accounts just got bigger. You now get 50,000 On-demand API requests a month, 30 monthly Snapshot requests, and free access to Structured Contents Snapshots. Existing accounts are upgraded automatically.
-
Parsing raw wikitext into a clean text corpus is notoriously hard. Databricks engineers used Wikimedia Enterprise’s Structured Contents endpoints and Apache Spark to convert millions of Wikipedia articles to Markdown at scale, skipping the regex-heavy parsing layer entirely.

-
Ryland Hale wanted to make it easier for people to see what their politicians are actually doing. His project, CivicLens, pulls from sources like Congress.gov, LegiScan, the FEC, and Wikipedia to show voters exactly who represents them and how they vote. But turning raw government databases into a readable website requires a massive amount of

-
Structured Contents endpoints now parse and return article images and lists as structured JSON, directly within each section of a Wikimedia project article. Both features are available today in the On-demand API and Snapshot API.

-
Wikidata API endpoints are now part of Wikimedia Enterprise’s On-demand and Realtime APIs. Use your existing access token to query structured entity data, multilingual labels, and cross-language article links alongside Wikipedia and other Wikimedia project data.

-
Aligned AI utilizes the Wikimedia Enterprise Snapshot API to download and host comprehensive datasets from Wikimedia projects directly on their devices. This allows people to use Aligned’s offline search tool while still finding relevant Wikipedia articles to read and learn from.

-
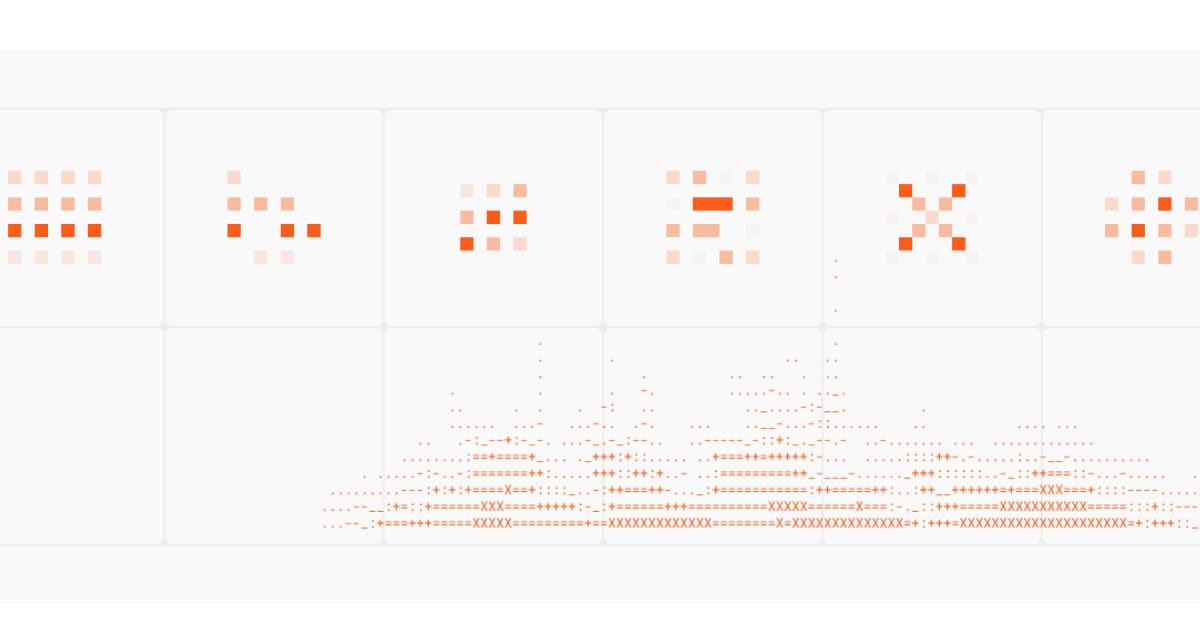
Firecrawl has partnered with Wikimedia Enterprise to support the millions of monthly requests their users make to retrieve Wikimedia project data. With Firecrawl aiming to become the main infrastructure layer between web data and AI, getting Wikimedia data in any format for agentic workflows becomes as easy as a single request.
-
Ecosia, the search engine that uses 100% of its profits for the planet, provides a search experience with a positive environmental impact. Ecosia is conscious about its data sources: it aims to provide search functionality that provides clear and truthful results quickly, with links to sources and correct attribution. That’s why Ecosia partnered with Wikimedia

-
This seminar saw over 220 attendees, both in-person and online, for this talk exploring how the Wikimedia Foundation can stay human-centric while also innovating alongside current developments in AI.

-
Mistral AI and Wikimedia Enterprise are excited to announce the start of a three-year partnership. Data from Wikipedia and other Wikimedia projects is indispensable as a source of knowledge for Mistral’s AI projects, such as its AI assistant Le Chat.

-
Wikipedia celebrates 25 years of human-created knowledge on 15 January 2026. To mark this milestone, Wikimedia Enterprise is publicly announcing partnerships with Amazon, Meta, Microsoft, Mistral AI, and Perplexity. Learn how our infrastructure delivers human-governed knowledge at scale.

-
Read our full annual wrap-up to explore how 2025 marked a fundamental shift in open knowledge. From Wikipedia’s recognition as a Digital Public Good to the launch of Parsed Tables and Quality Scoring models, discover how we are helping developers build a sustainable future for ethical data with Wikimedia Enterprise.

-
Reef Media is building a comprehensive platform to help users analyze media for its strengths and weaknesses, creating a more informed public. One of the key datasets underpinning their technical strategy is a robust, verifiable data source: Wikimedia data extracted through the Wikimedia Enterprise Snapshot API.

-
Learn about the intersection between generative AI data and open, trusted datasets in the talks by Wikimedia Enterprise, MLCommons, and the AI Alliance at NeurIPS.

-
Access Wikipedia’s most valuable tables as structured JSON with the new Parsed Tables feature from Wikimedia Enterprise. Instantly convert complex tables into clean, machine-readable data without scraping. Enhance your AI, search, and knowledge graph projects with reliable, human-curated facts that were previously locked away in HTML and wikitext.

-
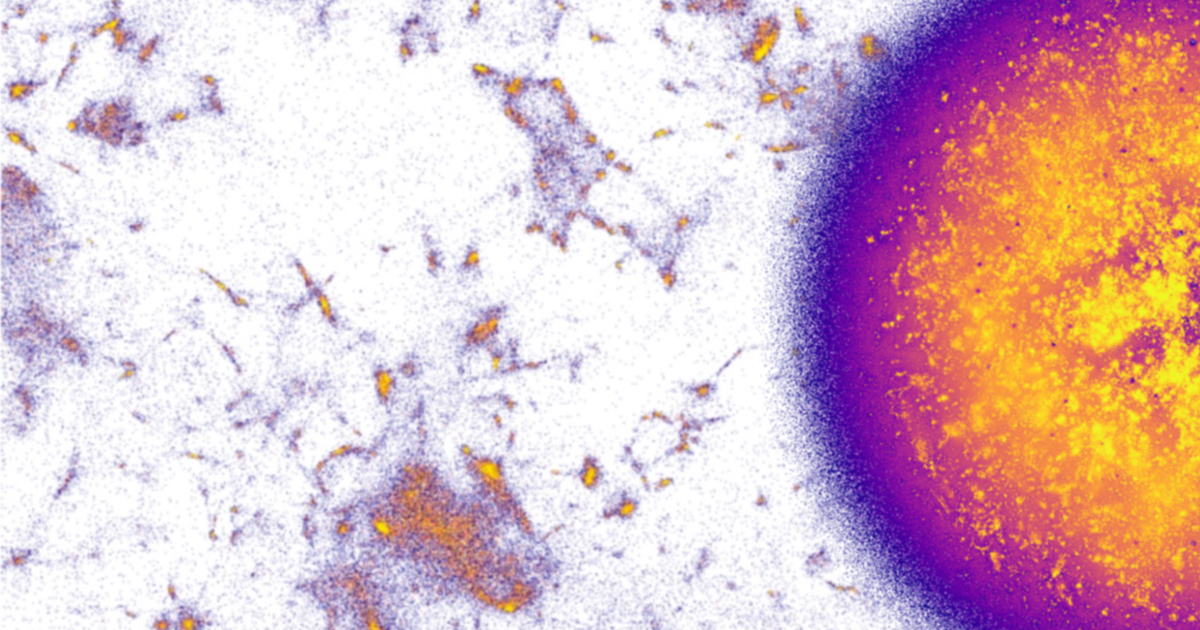
Nomic AI used Wikimedia Enterprise’s Structured Contents dataset, via Hugging Face, to build the first full open-source vectorization of multilingual Wikipedia. Their work highlights how structured open data can accelerate AI research, improve model performance, and enable new forms of data visualization.
-
Explore Wikipedia content in a clean, structured format with our new beta dataset on Kaggle. Built from our Snapshot API using the Structured Contents beta, it’s ideal for data science, ML training, and experimentation.

-
Wikimedia Enterprise is partnering with ProRata.ai to power its new search engine, Gist.ai, with reliable, human-curated Wikimedia content. The collaboration supports a sustainable content ecosystem through transparent attribution and API-driven innovation—ensuring creators are credited and content remains discoverable in the AI era.

-
The latest API release boosts Wikipedia data integration with parsed references in JSON and two quality scoring models – Reference Need and Reference Risk. These enhancements streamline citation access and improve content reliability for developers.

-
Wikimedia Enterprise joined Creative Commons at SXSW 2025 on March 9th in downtown Austin for a day of insightful conversations and panels exploring the intersection of artificial intelligence and open data. The discussions emphasized the critical importance of protecting and ethically advancing open access principles amidst rapid technological growth. The event brought together industry leaders,
