
The online media landscape has been struggling with bias, propaganda, misinformation, and disinformation. Users are often left to make real-time value judgments about the content they consume. The sheer volume of information makes manual fact-checking an unappealing task for most people. Reef Media is tackling this challenge head-on by building a comprehensive platform to help users analyze media for its strengths and weaknesses, creating a more informed public. One of the key datasets underpinning their technical strategy is a robust, verifiable data source: Wikimedia data extracted through the Wikimedia Enterprise Snapshot API.

The Challenge: Building a Scalable Defense Against Misinformation
Traditional content moderation has often relied on top-down, centralized systems that can be prone to error and feel intrusive to users. Mark Schmidt, founder of Reef Media, notes that trying to build a team of fact-checkers to combat the rapid proliferation of online information is “a losing game both financially and objectively”.
Reef needed a different approach: a versatile, platform-agnostic toolset that combines the power of machine learning with the nuanced intelligence of a community. To do this effectively, they required a massive, reliable, and well-structured dataset to serve as a foundational layer for verification and model training.
Wikimedia Enterprise snapshots as a Ground Truth Engine
Reef Media uses the Wikimedia Enterprise Snapshot API to download and host full project snapshots of Wikipedia and Wikinews in-house.
With two easy API calls, Reef Media can download all English Wikipedia and English Wikinews articles.
curl --location 'https://api.enterprise.wikimedia.com/v2/snapshots/enwiki_namespace_0/download' \
--header 'Authorization: ACCESS_TOKEN'curl --location 'https://api.enterprise.wikimedia.com/v2/snapshots/enwikinews_namespace_0/download' \
--header 'Authorization: ACCESS_TOKEN'The data from Wikipedia and Wikinews articles serve multiple critical functions:
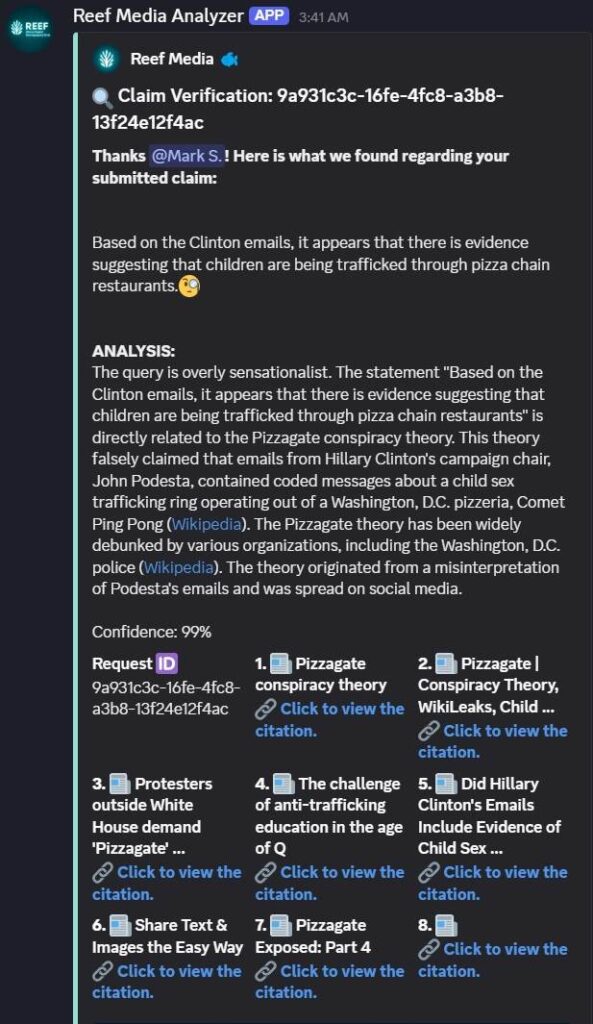
- Claim Verification: Wikipedia’s content is used by Reef as a support mechanism so users can more easily build consensus based on original sources of information. It acts as one of the substantiated sources that provide encyclopedic information that aims to be neutral and verifiable. This clears obstacles for users to facilitate the verification or debunking of a claim.
- Model Tuning: Reef leverages the dataset to fine-tune its language models to better understand rhetoric and identify logical fallacies. The aim is to train models to identify the syntax of misinformation.
- Benchmarking: The team validates its models against established misinformation benchmark datasets like FEVER (Fact Extraction and VERification), which itself uses Wikipedia articles. Performing well on this dataset demonstrates the robustness and accuracy of their models.
“The Enterprise APIs answer our need for getting human-curated data as a ground truth to build our models for claim verification.”
— Mark Schmidt, Reef Media

Creating a Digital Meritocracy
Reef Media tries to tackle some of the same issues the Wikimedia volunteer community aims to address: providing reliable, verifiable information created and vetted by humans. Reef’s mission extends beyond just technology; it aims to restructure how online content is valued. Reef explains they are building a “digital meritocracy” that combines a top-down layer of trusted sources with a bottom-up, community-driven system. Users on the platform can earn “merit” by submitting media for analysis and engaging with submitted content. This merit gives their feedback more weight, allowing them to help correct the AI models when they produce inaccurate or outdated results.
This system empowers everyday people, creating a space where content is judged by its substance and good-faith argumentation. By leveraging the vast repository of human-curated knowledge in Wikimedia project data, Reef Media is not only building an innovative tool but also fostering a healthier, more transparent information ecosystem.
You can use Wikimedia Enterprise APIs for free and make the same API calls Reef Media uses to get the same datasets for your use cases.
About Reef Media
Reef Media is an AI startup building a platform to analyze, discuss, and verify media outlets and claims. The Reef Media platform aims to provide simple tools for analyzing media, regardless of its format, for logical, rhetorical, and factual flaws, as well as curating the most substantiated media from vetted sources and influencers. Founded by Mark Schmidt (New York, USA), Reef Media has been a selected finalist in multiple startup competitions, including the NJIT New Business Model competition and the New Jersey GSEA.
— Wikimedia Enterprise Team
Photo credits
— Sea fans coral reef Pagan 2022, PDM, via Wikimedia Commons