
This latest release enhances our API offerings with new capabilities for Wikipedia data integration. As part of our Structured Contents initiative, this update introduces parsed references and citations embedded in article JSON payloads, making citation data more accessible and machine readable while preserving its context. Additionally, we’re rolling out two new reference quality scoring models – “Reference Need” and “Reference Risk” – to provide insights into content reliability. These additions streamline access to Wikipedia’s knowledge base and offer metrics to evaluate its quality, benefiting developers in diverse applications.
This article explores the parsed references and citations feature, followed by an overview of the scoring models and their practical uses.
What’s in this article:
Importance of References & Citations in Wikipedia Ecosystem
References and citations underpin Wikipedia’s credibility, tying every piece of information to verifiable sources. In Wikipedia, inline citations appear directly after the content they support – typically in square brackets – connecting facts to their corresponding entries in the references section. For developers and content reusers, this system is invaluable: structured access to these reliable sources offers deeper insights and ensures data integrity across applications. The new JSON parsing of references simplifies this process, moving past the hurdles of Wikitext or HTML scraping to deliver precise, machine-readable metadata while keeping its tie to the original context intact. This structured format upholds the trustworthiness of Wikipedia’s ecosystem and lets users trace sources effortlessly, enhancing the quality and accuracy of data-driven projects. As knowledge evolves, these citations provide a clear path to original materials, amplifying the value of Wikipedia’s content for technical innovation.
Parsed References and Citations
This API feature embeds parsed references in a new dedicated object and links citations to them within the sections array inside has_parts. Each paragraph object in a section includes a citations object tying inline citations – such as those marked by unique identifiers like cite_note-1 – to their full reference details elsewhere in the payload. For example:
"has_parts": [
{
"type": "paragraph",
"value": "...article paragraph content...",
"links": [...],
"citations": [
{
"identifier": "cite_note-1",
"text": "[1]"
}
]
}
]These citations, parsed at the paragraph level, use their identifiers to connect to the references object, where metadata is structured as key-value pairs (e.g., title, URL, access date) alongside the text as it appears on the page. This approach eliminates the inefficiencies of manual detection, parsing and extraction, delivering reliable, machine-readable data ready for immediate use in myriad workflows. A sample web reference might look like this:
{
"identifier": "cite_note-1",
"type": "web",
"metadata": {
"access-date": "2024-03-11",
"language": "en",
"title": "Cuphead in the Delicious Last Course critic reviews",
"url": "https://www.metacritic.com/game/cuphead-in-the-delicious-last-course/critic-reviews/?platform=xbox-one",
"website": "www.metacritic.com"
},
"text": {
"value": "\"Cuphead in the Delicious Last Course critic reviews\". www.metacritic.com. Retrieved March 11, 2024.",
"links": [
{
"url": "https://www.metacritic.com/game/cuphead-in-the-delicious-last-course/critic-reviews/?platform=xbox-one",
"text": "\"Cuphead in the Delicious Last Course critic reviews\""
}
]
}
}Docs / Data Dictionary links: References schema. Citations schema.
Reference Types
The parsed references encompass a broad range of source types cited in Wikipedia articles, ensuring comprehensive coverage to give users a full view of each citation’s origin and context. These include web pages (with URLs and access dates), books (with authors, titles, and publication details), magazines (with issue numbers and publishers), news articles (with headlines and outlets), and other formats like journals or reports, each with tailored metadata (more details linked below in Further Reading).
Availability
On-demand API Structured Contents Beta Endpoint: Available for all Wikipedia languages, providing real-time access to parsed references and citations.
Snapshot API Structured Contents Beta Endpoint: Available for six languages—German (DE), English (EN), Spanish (ES), French (FR), Italian (IT), and Portuguese (PT)—offering a static, pre-processed dataset of structured content.
Note: Structured snapshots are part of an early beta release intended for QA testing with our testing partners to help refine the endpoint before a broader beta release. If you are interested in becoming a testing partner, please express your interest to our sales team. Wikimedians can also access this beta via their accounts on Wikimedia Cloud Services.
Reference Need and Reference Risk Quality Models
Alongside structured references, this release introduces two machine learning-based reference quality models for assessing reference quality: “Reference Need” and “Reference Risk,” both accessible within the version.scores object.
The Reference Need model, detailed at Multilingual Reference Need, identifies text sections needing additional citations. A higher reference_need_score indicates a stronger need for sources inline with Wikipedia’s ‘verifiability’ policy (more details linked below in Further Reading). Reference Need score is located at version.scores.referenceneed.reference_need_score.
The Reference Risk model, outlined at Language-agnostic Reference Risk, evaluates the reliability of existing references in an article revision. It generates a reference_risk_score – an overall score aggregating the quality of all references on the page –based on factors like domain survival probability. It’s a combined score of all references on the page. A higher reference_risk_score means there is more risk in the article as the present references are considered less reliable. It’s located at version.scores.referencerisk.reference_risk_score.
Here’s a sample JSON payload showing both scores:
"referencerisk": {
"reference_risk_score": 0.7434499
},
"referenceneed": {
"reference_need_score": 0.3181818181818182
}These models provide developers with precise metrics to assess and improve Wikipedia data, from pinpointing citation gaps to flagging unreliable sources, all backed by robust machine learning frameworks. Below are some research figures and data points about the effectiveness of these models in the Wikipedia ecosystem (source).
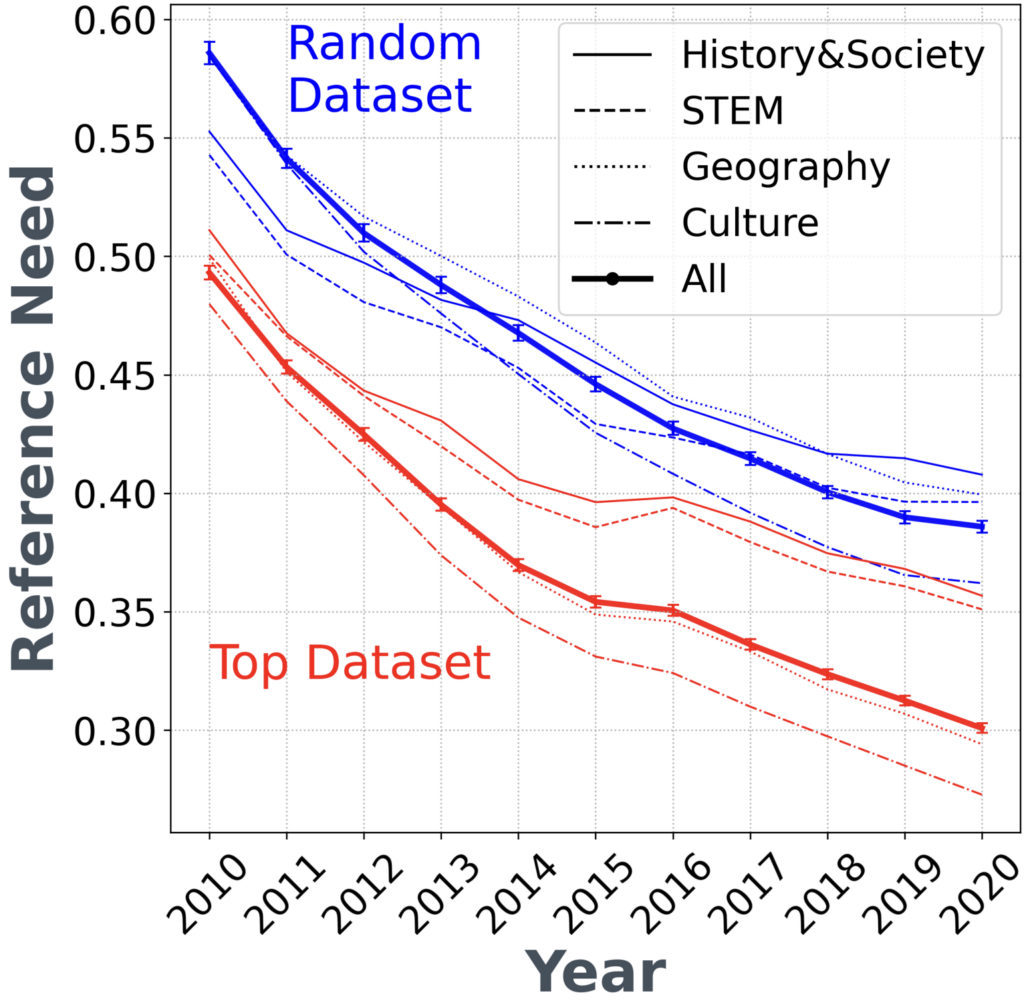
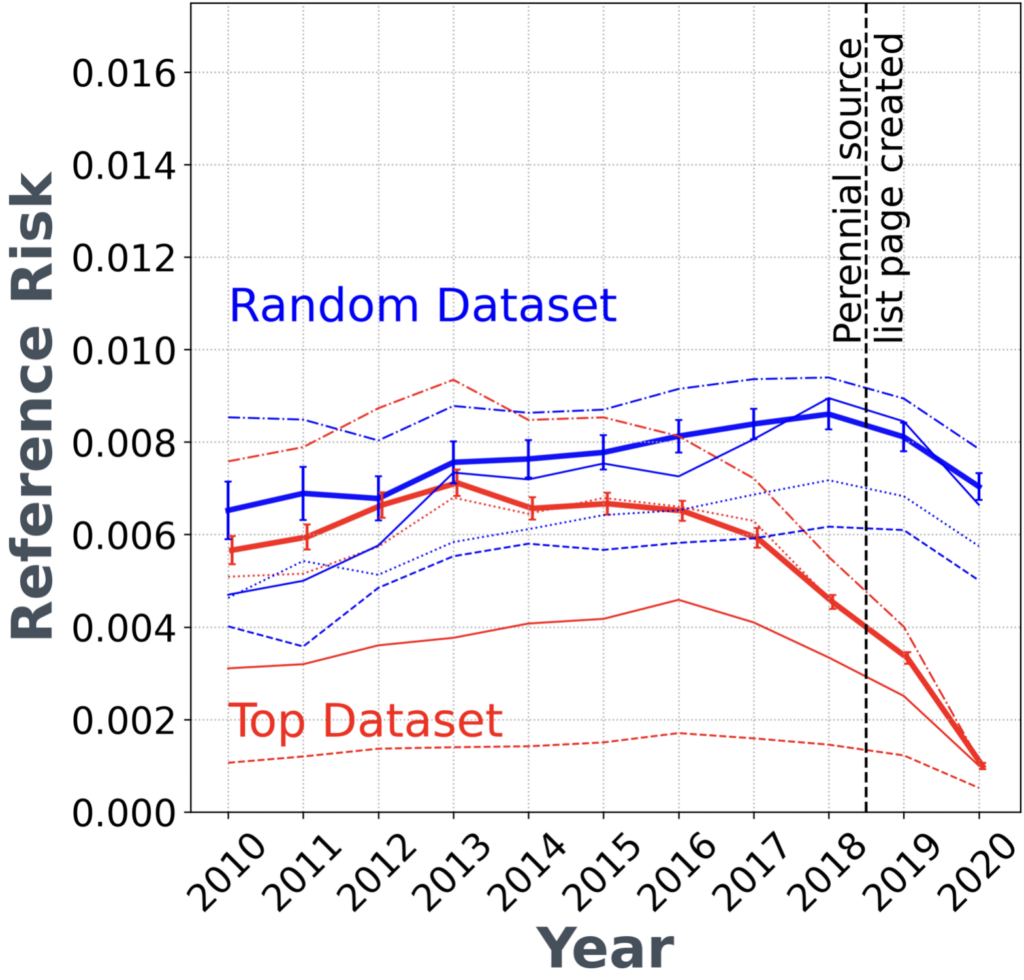
Availability
Reference Quality Scores: Available across multiple endpoints – Snapshot API, Snapshot Structured Contents, On-demand API, On-demand Structured Contents, and Realtime Batch – offering flexibility for both real-time and batch processing needs.
Get Started with these Features Now
These new features are live and available now. If you haven’t already, sign up for free API access to start integrating parsed references, citations, and reference quality scores into your projects. This release marks a significant step forward in making Wikimedia project data more actionable and reliable for developers. We’re excited to see how these tools will shape the next generation of knowledge-driven applications.
Further Reading
- Read about our Structured Contents Initiative
- Citing Sources: Learn more about verifiability policy and citing sources at Wikipedia:Citing sources.
- Types of Citations with metadata: Learn more about citation formats at Wikipedia:Citation_templates#Examples.
- Research: Reference Scores Models: Dive into the methodology behind Reference Risk at Research:ReferenceRisk.
- Research: Reference Quality in English Wikipedia: Explore findings on citation quality at Research:Reference_Quality_in_English_Wikipedia.
- Research: Analyzing Sources on Wikipedia: Review source analysis studies at Research:Analyzing_sources_on_Wikipedia.
— Chuck Reynolds, Staff Product Manager, Growth