In the world of AI research, innovative datasets are often the catalyst for scientific breakthroughs. Recently, Brandon Duderstadt, founder and CEO of Nomic AI, leveraged our Structured Contents dataset via Hugging Face in a project that modernizes Wikipedia’s data representation for the AI era.
The Hugging Face dataset provided by Wikimedia Enterprise is a critical resource that empowers researchers to build more advanced and nuanced AI models. Drawing from Wikimedia’s vast and diverse range of human knowledge, this dataset has become an indispensable tool for natural language processing (NLP) tasks, such as text classification, sentiment analysis, and knowledge extraction.
This same dataset, also available on Kaggle, consists of fully preprocessed structured JSON output of all French and English Wikipedia articles. It offers a clean and consistent format facilitating efficient data ingestion and model training. While the original dataset remains freely available, an enhanced version of the Structured Contents Snapshot with additional content features is available by contacting the Enterprise team.
Introducing Nomic AI
Nomic AI, AI-powered data visualization, is dedicated to making complex models more interpretable and accessible. Using their innovative approach to representing data, the company leveraged Wikimedia Enterprise’s dataset on Hugging Face to experiment with high-dimensional visualizations, enhancing the understanding of model architectures and relationships within data. This collaboration exemplifies how open datasets can accelerate AI advancements through strategic partnerships.
Open Source Vectorized Wikipedia
AI models and applications typically require unstructured data to be vectorized, or converted to a sequence of numbers, before they can be used. The vectorization process is typically done with specialized AI models called embedding models.
Previously, companies such as Co:Here released partial vectorizations of Wikipedia using proprietary embedding models. These are limited in utility due to their incomplete nature and reliance on closed source models.

{kind=link}
In a series of papers published at venues like ACL and CVPR, Duderstadt and his team address this challenge by developing the open source infrastructure and methods necessary to vectorize and analyze all of multilingual Wikipedia.
They start by introducing Nomic-Embed-Text-v2, the first fully open source state-of-the-art multilingual embedding model. This model, whose training data includes parts of the Wikimedia Enterprise Structured Contents dataset, is able to convert articles in any language into vectors that can be used by AI models.
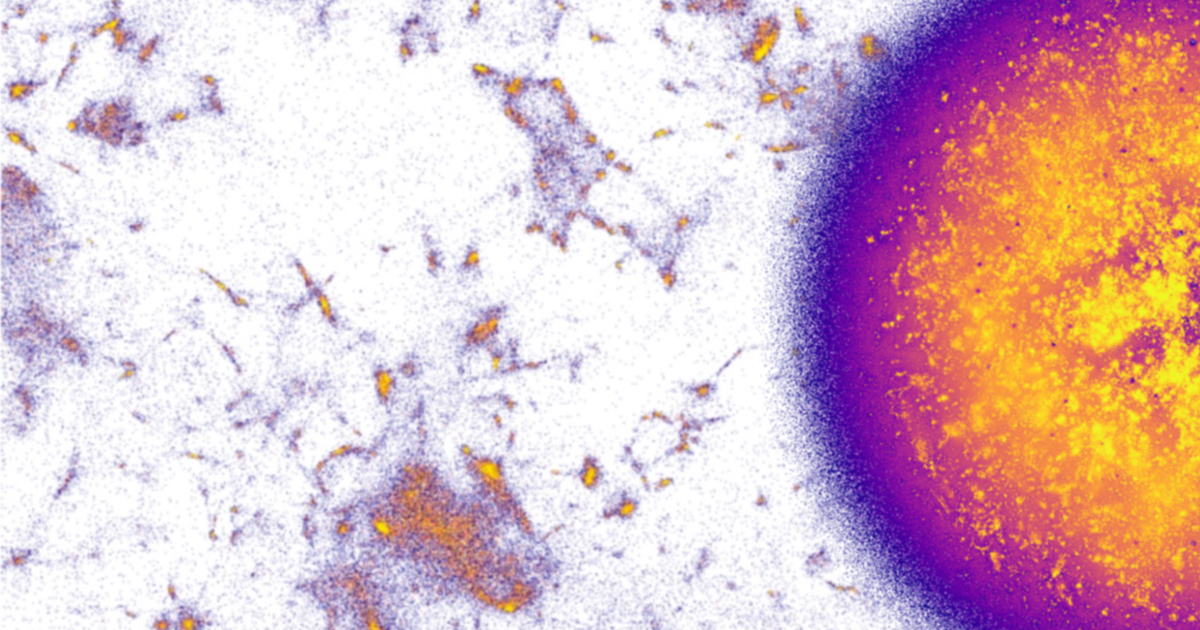
The team ran Nomic-Embed-Text-v2 on the entirety of our dataset to create WikiVecs, the first end-to-end open source vectorization of all of multilingual Wikipedia. The WikiVecs dataset can be used to power a wide range of AI applications, including Retrieval Augmented Generation (RAG) workflows, quantitative analysis and data visualization. Finally, the team developed NOMAD Projection, a scalable vector data visualization algorithm that enables the computation of the first complete picture of multilingual Wikipedia (shown below).
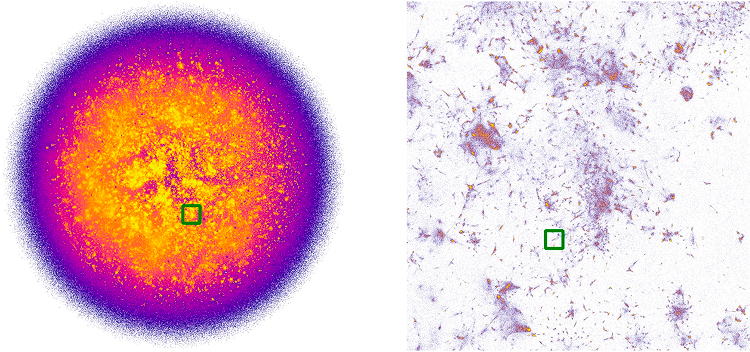
Continuing this analysis, Duderstadt and his team use WikiVecs and NOMAD Projection to surface content silos across different language editions of Wikipedia. The silos they discover span a wide range of topics, from nuclear scientists to biblical codex, highlighting the utility of AI ready datasets and visualization methods.
Looking Ahead
This collaboration between Wikimedia Enterprise and Nomic AI underscores the value of open-access datasets in accelerating AI research. By providing researchers with access to vast, high-quality structured datasets, Wikimedia Enterprise continues to play a pivotal role in advancing AI technology. As demonstrated by Duderstadt’s work, these structured datasets we’re building create innovative methodologies, improve model performance, and introduce new ways of visualizing and understanding AI-driven data. The future of AI is one of increasing collaboration.
Duderstadt and his team are excited to get their datasets and methods into the hands of the open source community, via 2025 ACL and CVPR conferences.
Read more about the Structured Contents dataset they used, available on Hugging Face and Kaggle, as well as our APIs that generated it. To get the latest Structured Contents Snapshot dataset with added features beyond what’s freely available; contact us to get started.
— Shaindel Tomasovitch & Francisco Navas