
SimPPL, a nonprofit research organization, uses Wikimedia Enterprise APIs to power its investigative tools. The organization builds open-source applications that map public conversations, track coordinated campaigns that drive the narrative on social media, and provide context to digital news. SimPPL monitors the information ecosystem by indexing posts receiving 100 billion views a month across 9 social media platforms. To turn this mountain of text into verifiable intelligence, SimPPL cross-references social media claims against the structured data provided by Wikimedia Enterprise.
SimPPL launched as an effort to improve global access to reliable information. They started working on social media analysis projects anticipating many social media platforms (such as X and Reddit) would start restricting access to their APIs, a period popularly known as the ‘API apocalypse’. This only made it harder for researchers and journalists to analyse what these platforms were producing.
“The ‘API apocalypse’ was an inflection point for me. We, as social media users, are the people creating the data used to advertise and monetize these platforms, but now we don’t have programmatic access to that same data. So during my PhD I started building systems that allow us to independently analyze and understand how these platforms influence our decisions.”
— Swapneel Mehta, Co-founder of SimPPL
Arbiter investigates who is shaping your social media feed
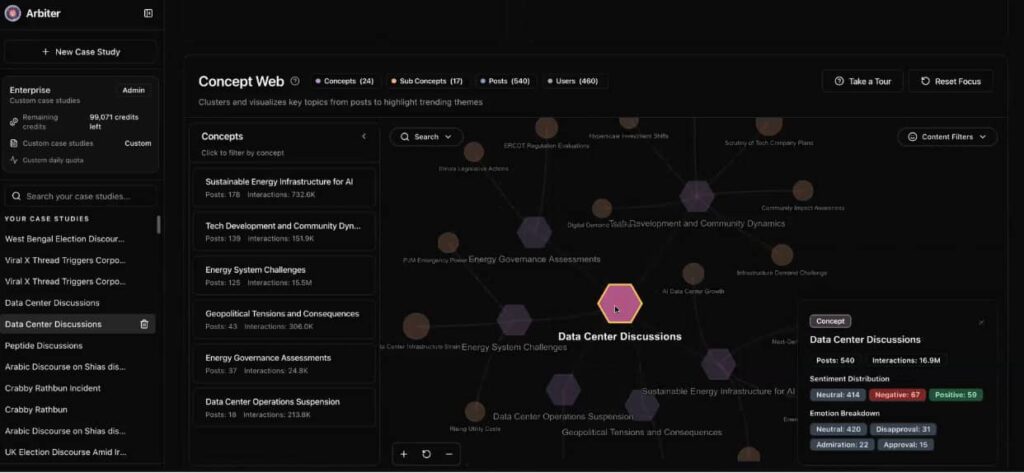
SimPPL’s flagship platform, Arbiter, is an investigative environment for journalists and researchers tracking how coordinated networks manipulate public feeds. For example, when analyzing a major trend, such as online debates surrounding the creation of a new AI training data center, Arbiter automatically breaks down thousands of social posts into distinct sub-narratives, showing which accounts are driving specific angles before this influences public conversations and policy outcomes.
To evaluate these narratives without introducing systemic bias, Arbiter identifies which accounts make which claims, classifies which claims are noteworthy, and then fact-checks them. Fact-checking involves comparing claims to what trusted, peer-reviewed, neutral outlets say about them, such as PubMedia and, of course, Wikipedia.
For every extracted claim group, Arbiter selects keywords to search an extracted snapshot of all of English Wikipedia for relevant articles. Arbiter periodically downloads all of Wikipedia using the Wikimedia Enterprise Snapshot API for full-text search. When relevant articles are found, Arbiter sends an API request to the Wikimedia Enterprise On-demand API to get the most recent version of that article. The claim is checked against any matching Wikipedia articles, pulling factual summaries and linking to relevant sources cited in the article.
EditBetter supports Wikipedia editors by providing context from other platforms
EditBetter reverses that flow. Where Arbiter uses Wikipedia data to evaluate social narratives, EditBetter feeds social context back to the Wikipedia volunteers editing topics that are being talked about in online discourse. These volunteers need to ensure a neutral point of view backed up by trusted sources, but that gets harder when many of the online sources are biased, part of misinformation campaigns, or rooted in public misperception.
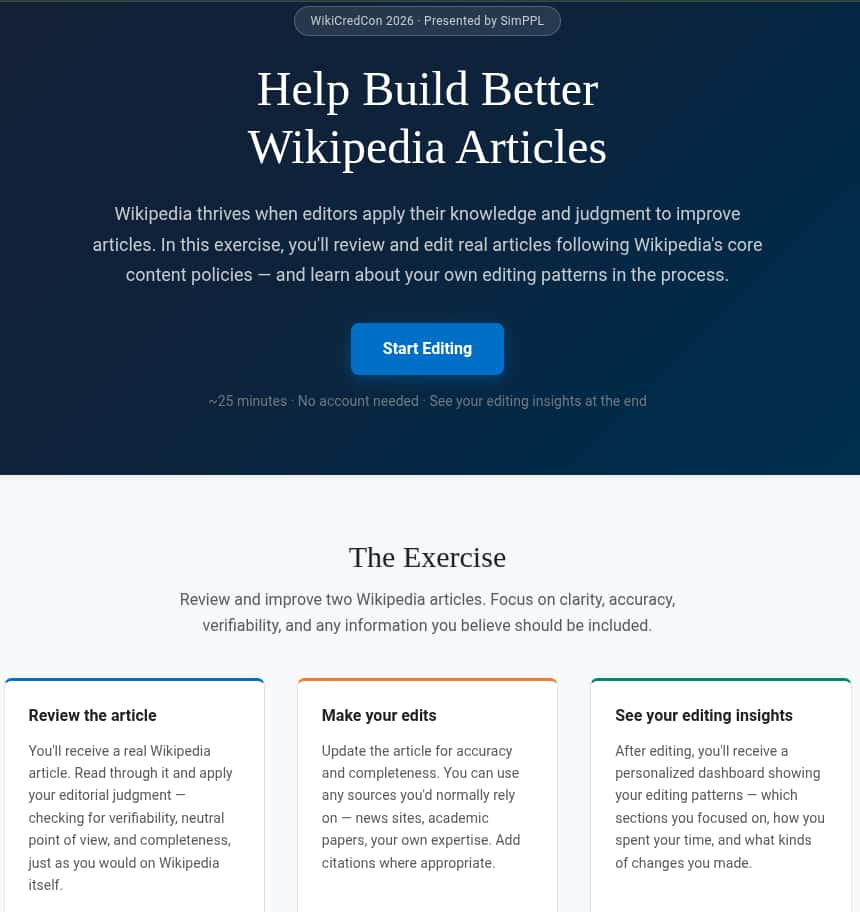
Through EditBetter, Mehta hypothesizes that showing real-time social media trends can improve an editor’s ability to refine an article.
“Our first step is checking whether providing this claims data improves an editor’s ability to bring a draft closer to the “gold-standard” article. If that works, our next step is to design extensions and MediaWiki gadgets for Arbiter so community members can query these tools directly while editing Wikipedia articles.”
— Swapneel Mehta, Co-founder of SimPPL
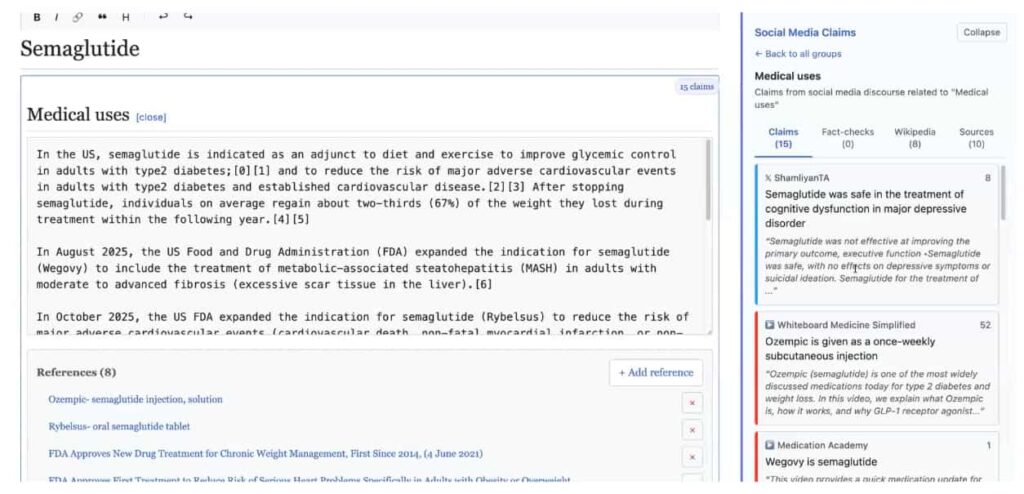
The application summarizes current social media claims about the article topic that is currently being edited. It also shows source-reliability ratings compiled from independent watchdogs, and surfaces related Wikipedia pages. This alerts the editor to widespread public blind spots, helping them correct those misperceptions.
The related Wikipedia articles are, once again, looked up by searching for related articles in a downloaded snapshot of English Wikipedia, provided by the Wikimedia Enterprise Snapshot API.
Community and Attribution
Transparency and accountability of information flows is core to SimPPL’s open-source work. In both Arbiter and EditBetter, information is accompanied by clear source attribution, ensuring that the work of volunteer editors in defining facts remains visible.
As SimPPL prepares to expand its testing with broader groups of Wikipedia editors, this project shows how high-volume data reuse can be run responsibly, supporting both digital media literacy and the open knowledge community. In a world where many platforms are becoming walled gardens, Wikimedia continues to value the digital commons as a crucial arena that needs to stay open and accessible for both human and algorithmic reuse.
Get Started with Wikimedia Enterprise
SimPPL uses the Snapshot and On-demand APIs to build search and retrieval over the world’s largest repository of open knowledge. You can do the same with Wikimedia Enterprise for free. Structured, high-volume project data lets you ground LLM and agentic applications, power semantic search and retrieval, or build custom data analytics pipelines.
– The Wikimedia Enterprise Team
About SimPPL
SimPPL is a nonprofit research organization that builds open technology to protect the integrity of digital news and online discussions. Founded by data scientists and computer engineers with backgrounds in civic integrity and trust and safety, SimPPL creates analytical systems that help journalists, researchers, and open knowledge communities understand online information manipulation. They’re actively supported by the YouTube Research API team and Bluesky Trust and Safety Team with data access that contributes to this work. Explore the tools at arbiter.simppl.org and editbetter.vercel.app.
Photo Credits
Étude de Danseuse, by Edgar Degas, 1895-1899, Public Domain, via Wikimedia Commons