Firecrawl and Wikimedia Enterprise are partnering to reform how AI agents access the world’s largest online repository of human knowledge. Firecrawl is a leading open-source API suite used to crawl websites for structured, reusable data. Users retrieve data via Firecrawl to power AI agents, chatbots, LLMs, and more. Firecrawl will integrate Wikimedia’s high-volume, commercial-grade Enterprise APIs into its infrastructure to support its users in retrieving Wikimedia project data.
Currently, Firecrawl already handles 2 to 3 million requests per month for Wikipedia data alone. Fetching this data requires spinning up headless browsers, repeatedly scraping the same pages, and navigating complex HTML structures. This process is unnecessarily resource-intensive for both Firecrawl and Wikimedia’s public infrastructure.
Firecrawl will soon start routing all requests for Wikimedia data directly through the Wikimedia Enterprise On-demand API.
The Intelligence Layer for AI
“Our goal is to be the intelligence layer for AI. Whenever an agent needs to find something on the web, we want to give it to them in a fast and high-quality manner,” says Eric Ciarla, co-founder of Firecrawl.
Firecrawl gets over 17 million downloads and is positioned among the top 150 GitHub repositories globally. Its straightforward approach to data extraction has driven rapid adoption across the AI developer community.
“We proactively reached out because Wikimedia projects are the most important sources of information on the planet,” Ciarla adds. “Using Wikimedia Enterprise APIs means better efficiency on our side; instead of building our own data pipelines and using virtual browsers that constantly scrape Wikipedia pages, we can tap into the robust Enterprise APIs that provide data in consistent formats. The Wikimedia Foundation providing these avenues of data delivery through their Enterprise products is a model we believe other publishers should follow.”
“Wikimedia projects are the most important sources of information on the planet”
Eric Ciarla
Getting clean web data for your agentic workflows in any format or schema you prefer becomes as easy as a single request with Firecrawl:
firecrawl scrape 'https://en.wikipedia.org/wiki/NASA'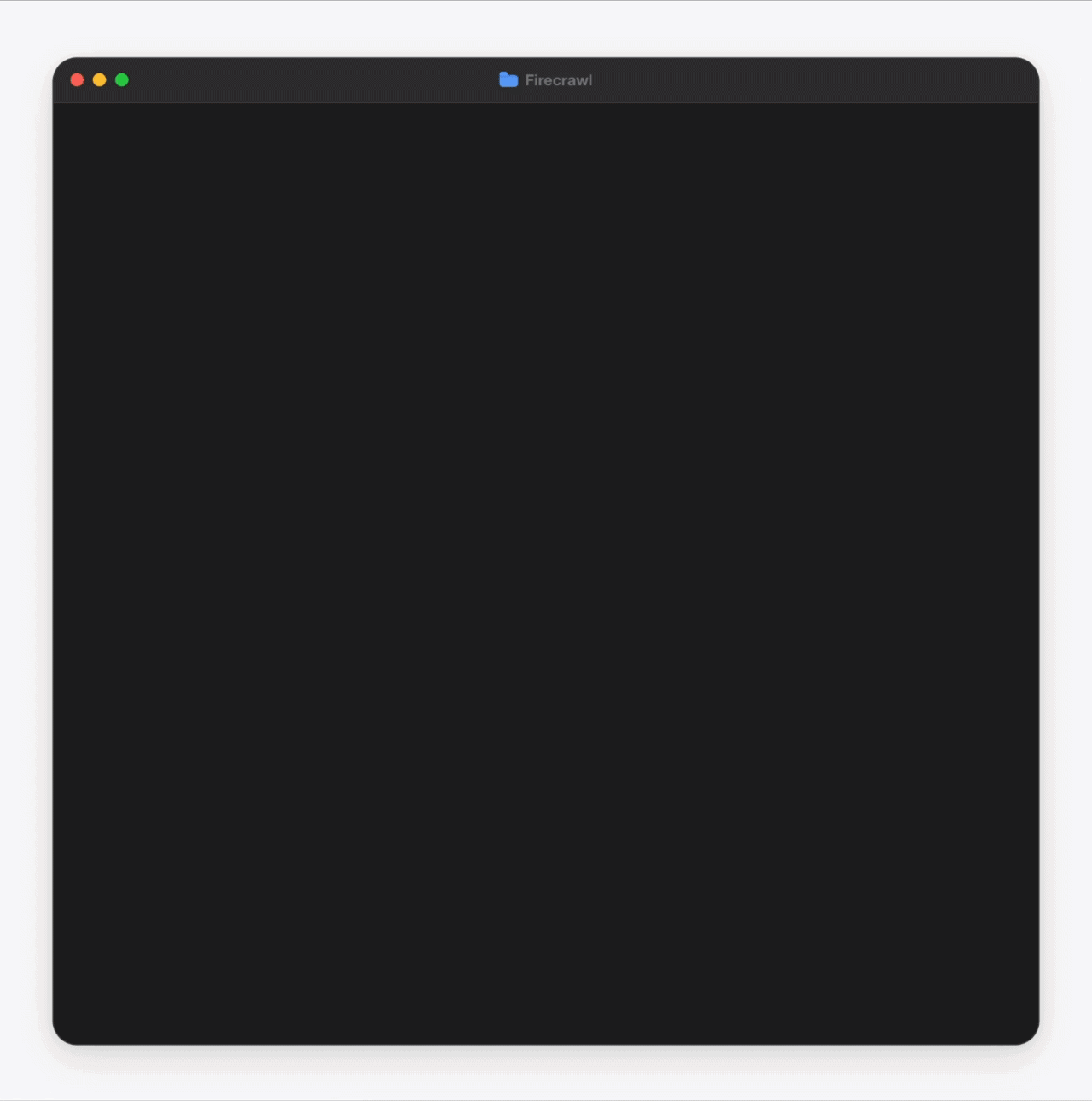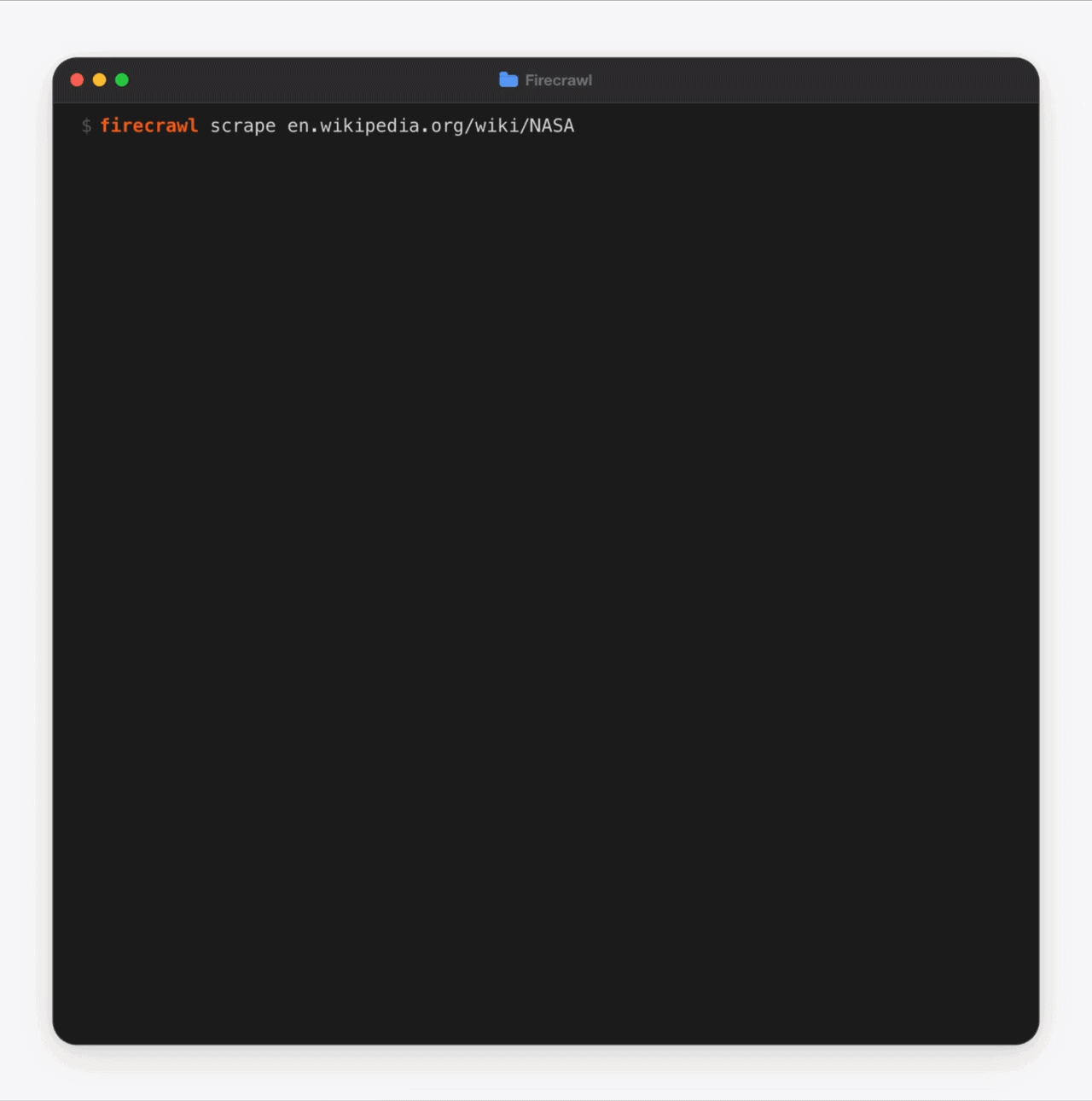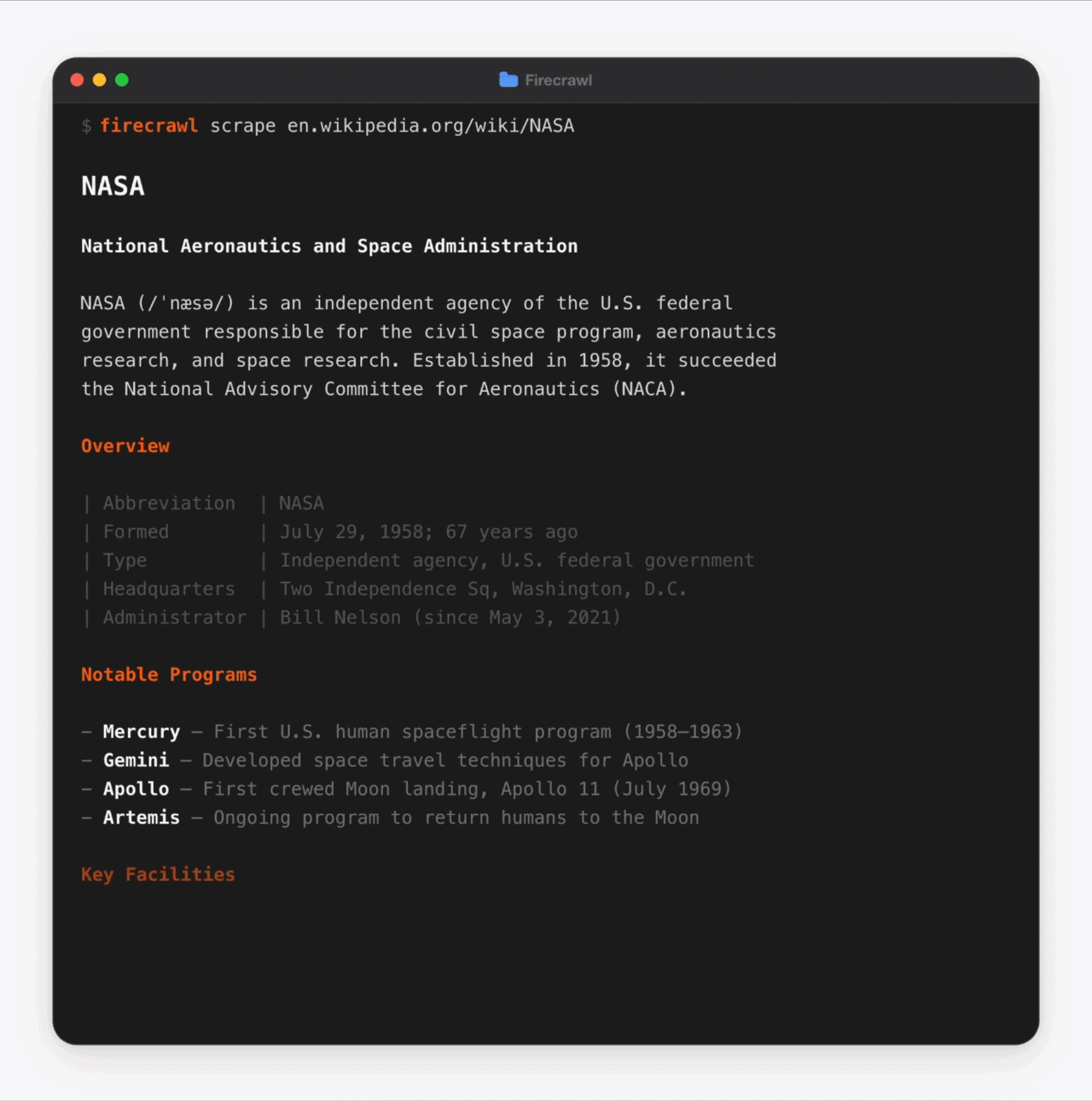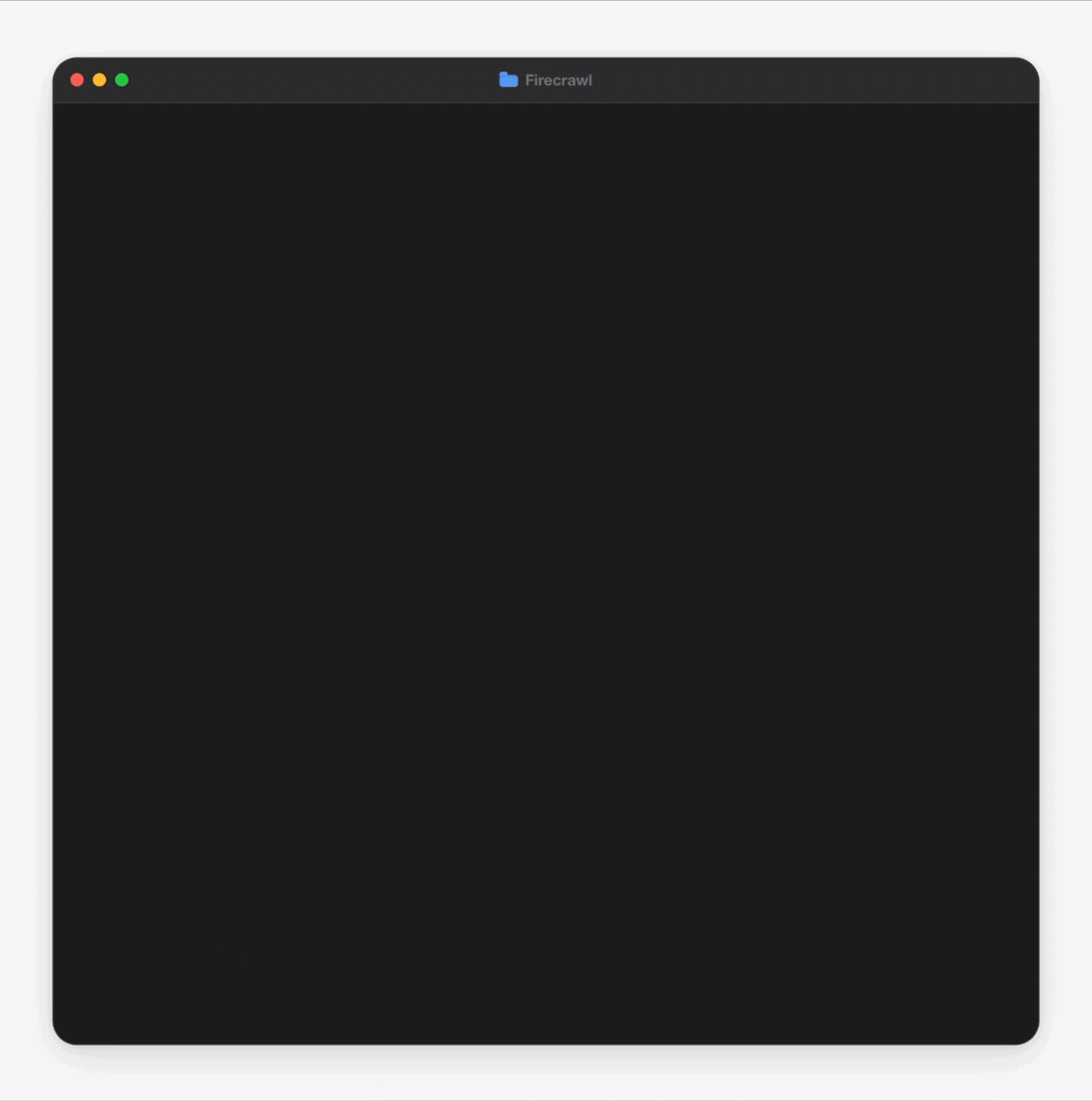
Firecrawl also provides its own agentic features that allow you to make requests in human language, so without any coding, you can use Firecrawl to handle the request “Get me all the info from Wikivoyage on the city of Paris.”
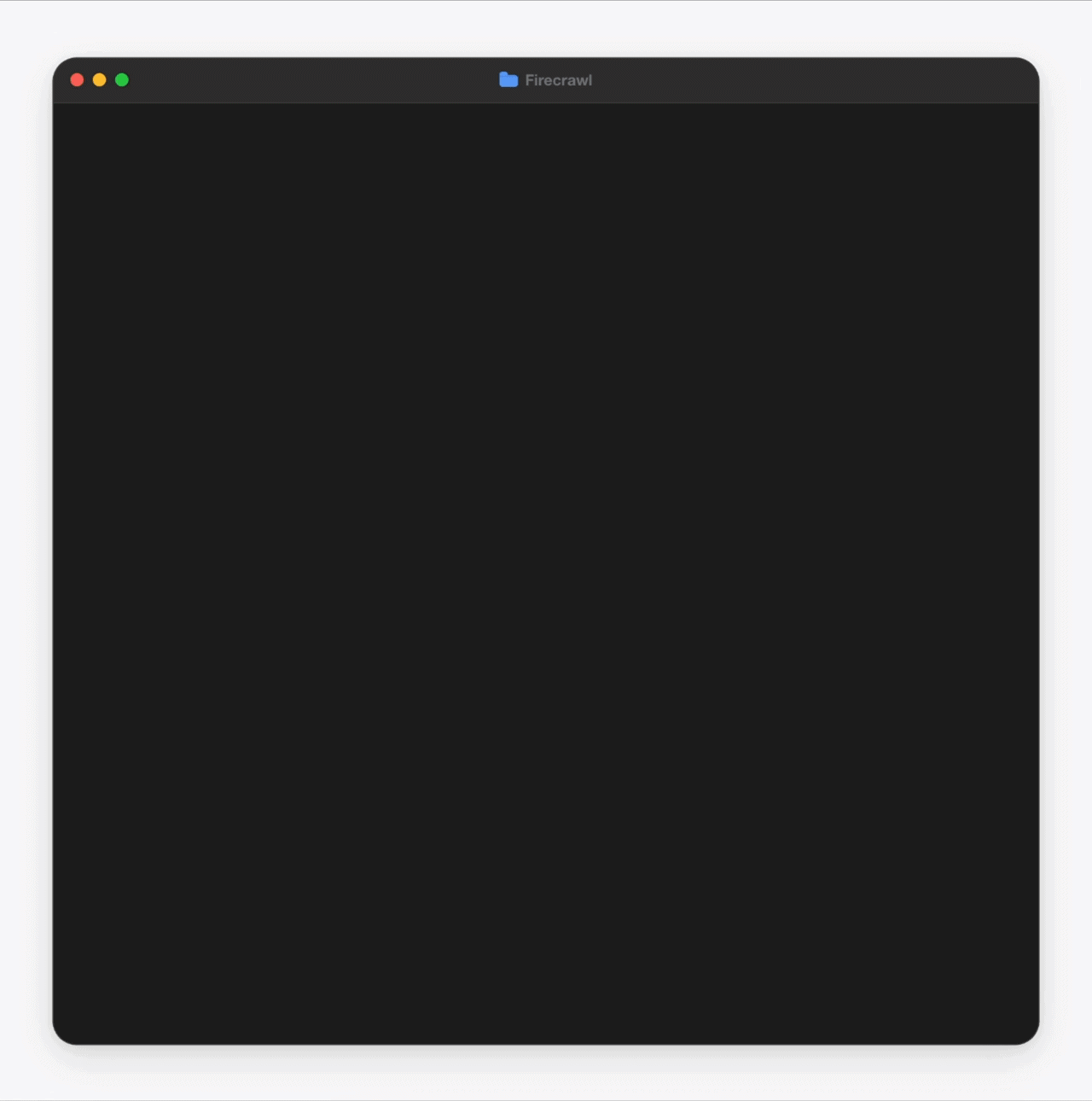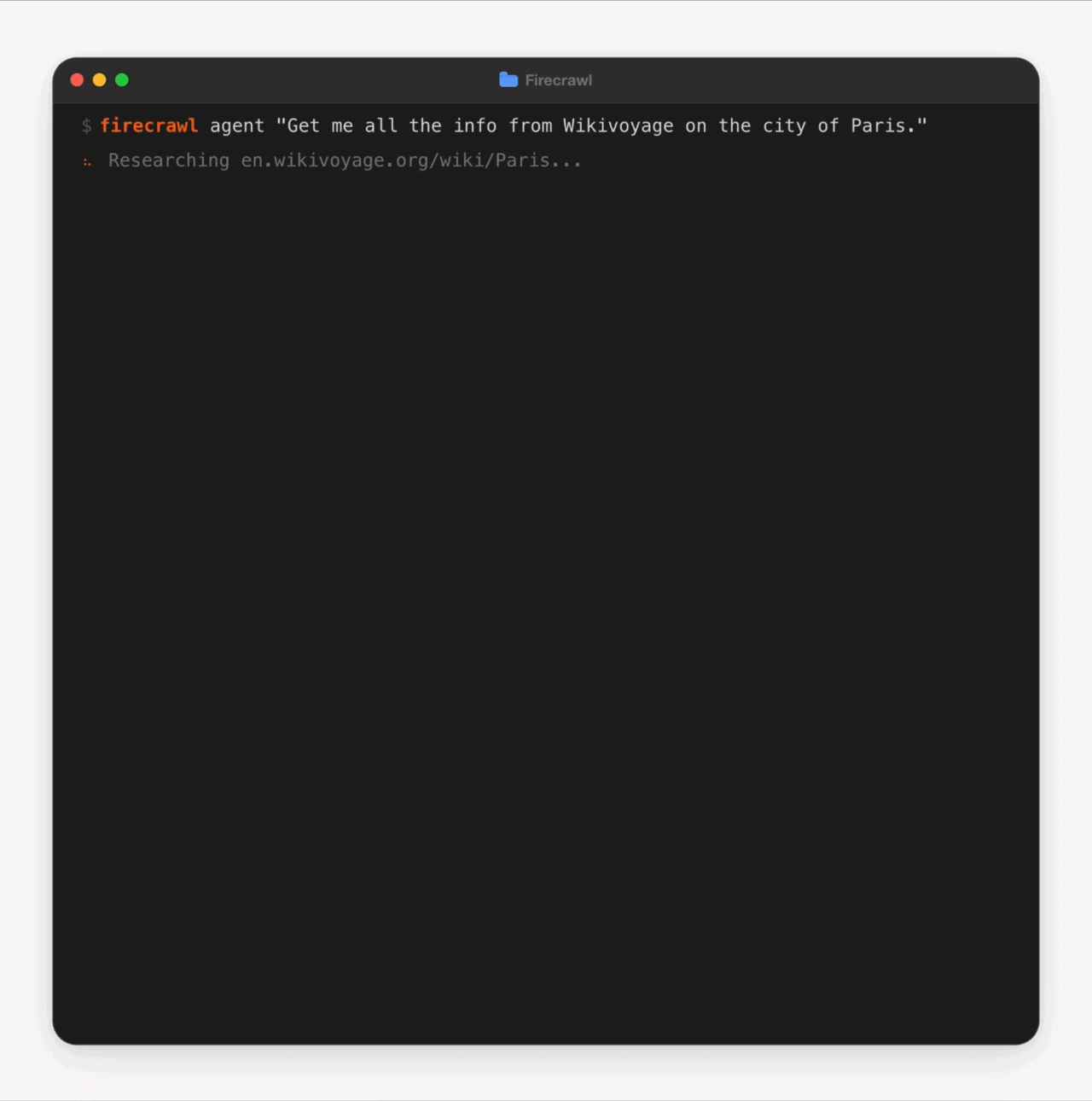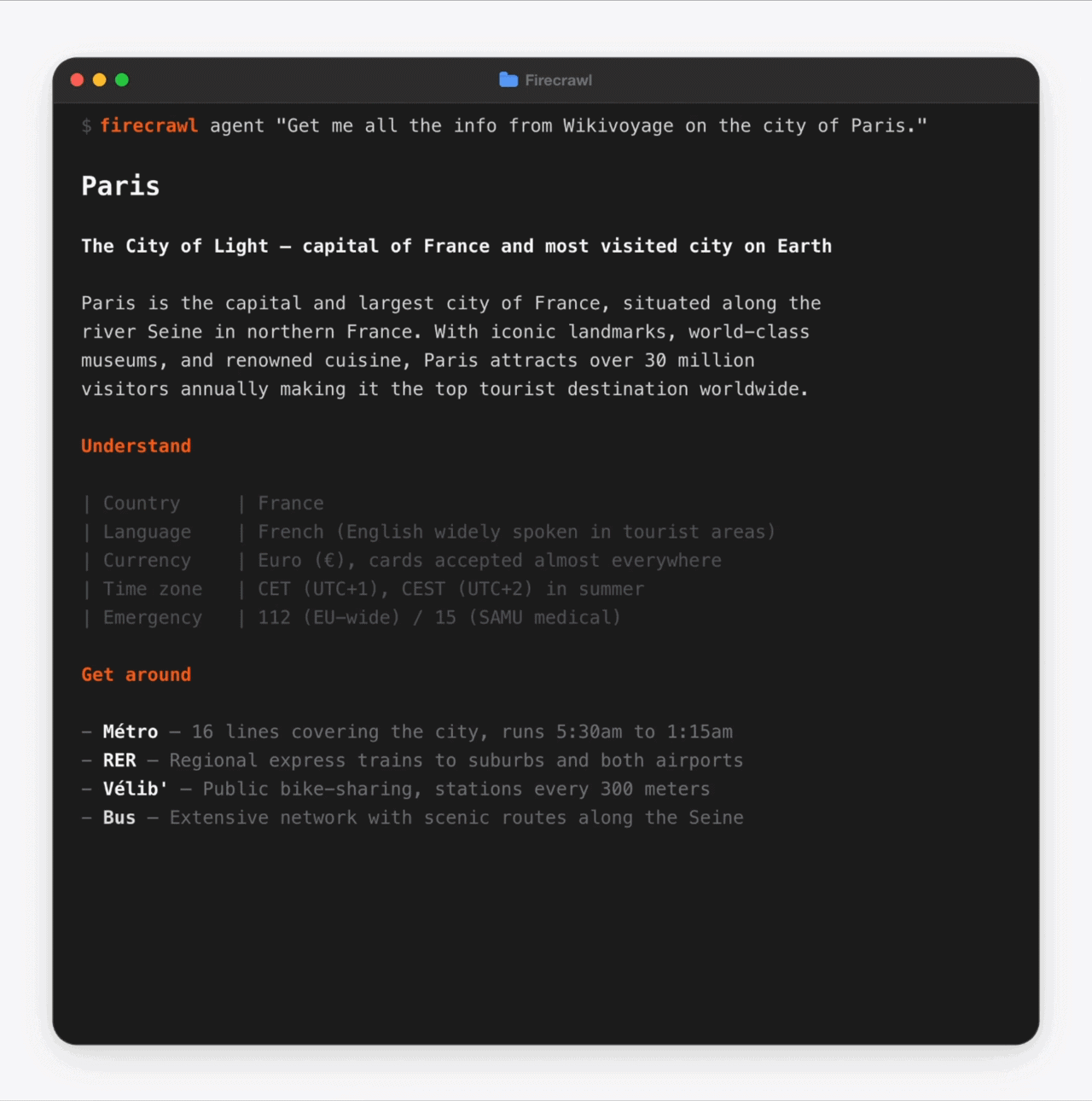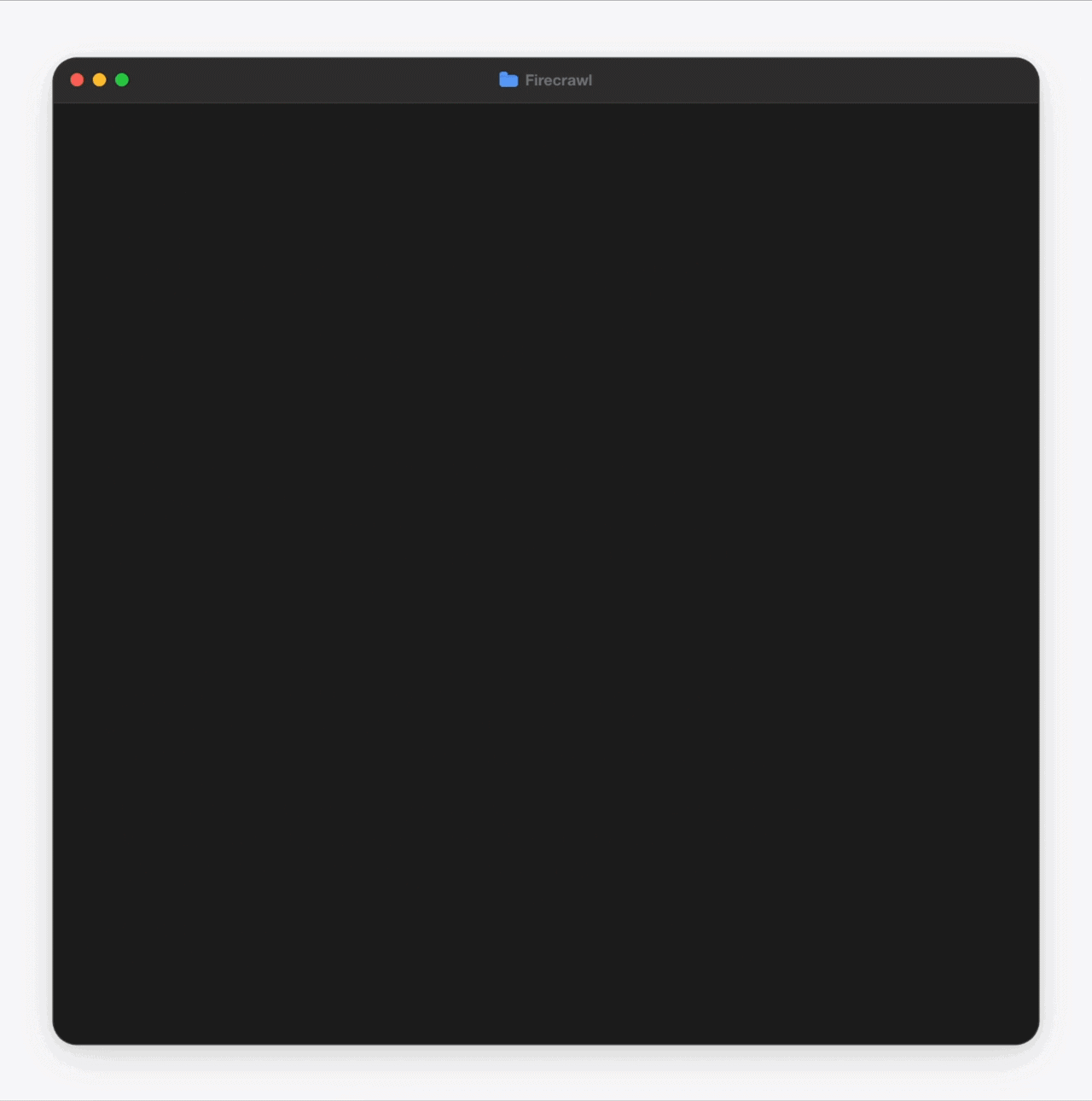
Firecrawl can be used as a skill in your favorite AI Agent, like Claude Code, or can be connected to any AI workflow through its MCP server.
Building for a Sustainable Web
Firecrawl encourages users to be transparent about their data sources, mirroring the Wikimedia Foundation’s values of public sharing and attribution. In Firecrawl’s search endpoint, source URLs are always provided back to the user, making it easy to build applications with attribution built in.
Attribution is also crucial to recognizing the work and commitment of volunteer editors and other community members in maintaining and shaping Wikimedia’s open knowledge. “The community members who write and edit these articles hold immense power in the age of AI,” says Ciarla. “They are providing the essential service of defining what is true. We have a lot of respect for these editors, and we want to ensure our infrastructure supports their work rather than just consuming it.”
This partnership reflects what responsible AI infrastructure looks like: high-volume data reuse that is fast, reliable, and supports the sustainability of the open knowledge community. We hope it points toward a future where AI and the open web grow together rather than at each other’s expense.
– The Wikimedia Enterprise Team
About Firecrawl
Firecrawl is the leading web data API for AI, serving as the essential infrastructure layer for developers and agents. With a focus on speed, quality, and open-source transparency, Firecrawl empowers the next generation of AI applications by providing a seamless way to “crawl” and “scrape” the web into LLM-ready formats.
Photo Credits
Firecrawl API overview, by Firecrawl, CC0, provided by Firecrawl